C/C++ 언어는 기본 데이터형을 최소화하기 위해서 많이 사용하는 형식의 데이터형만을 기본 데이터형
으로 정의하고 나머지는 프로그래머가 데이터형을 정의해서 사용할수 있도록 만들어졌습니다. 그래서
기본데이터형으로 char, int, float, double 을 제공하고 나머지 형식은 프로그래머가 배열, 포인터,
typedef, 구조체, 공용체 같은 문법을 가지고 직접 정의해서 사용하면 됩니다.
배열과 같은 문법으로 사용자 정의 데이터형을 만들면 동일한 데이터형만을 그룹지을수 있기 때문에
단순한 형태만 정의가능하다는 단점이 있는데 이것을 보완하기 위해 만들어진게 구조체라는 문법입니다.
구조체는 서로 다른 데이터형을 하나의 데이터로 군집화하여 사용할 수 있도록하는 사용자 정의
데이터형입니다. 따라서 구조체는 동일 데이터형을 군집화하여 사용할 수 있는 배열보다 자유로운
구성이 가능합니다. 그래서 사용자 정의 데이터형을 가장 잘 표현할 수 있는 문법입니다.
이 강좌에서는 구조체를 사용하여 사용자 정의 데이터형을 만드는 방법과 만들어진 데이터형을 사용하는
방법에 대해서 소개하도록 하겠습니다.
1. 구조체 정의하기
구조체를 정의할 때에는 다음과 같은 형식을 사용합니다. 이렇게 선언된 구조체명이 새로 만들어진
데이터형의 이름이됩니다. 즉, int char 와 같은 역할을 하게됩니다.
struct 구조체명 {
데이터형 변수명;
...
};
구조체는 struct 키워드를 선두에 명시한 후 사용할 구조체명을 적어서 정의합니다. 이 때 구조체
내부를 구성하는 데이터는 미리 정의된 데이터형으로 선언해야하고, 각 데이터는 " ; " 키워드로
분리해야합니다. 예를 들어 이름, 나이, 키, 몸무게와 같은 인적사항을 저장하는 People 이라는
구조체를 정의하면 다음과 같습니다.
struct People {
char name[20];
int age;
double height;
double weight;
};
위에서도 말했듯이 구조체 내부의 데이터는 미리 정의된 데이터형이여야하기 때문에 char, int, double
등과 같은 기본 데이터형 외에 다른 구조체나 사용자가 따로 정의한 데이터형을 사용하고 싶으면
이 구조체보다 먼저 정의되어 있어야합니다.
일반적이지는 않지만 한번만 선언해서 사용하는 경우 아래와 같이 구조체명을 생략해서 사용하는
경우도 있습니다. 즉, 구조체를 정의함과 동시에 data 라는 변수를 선언하기 때문에 이 데이터형을
다시 사용할 필요가 없다면 구조체명도 필요없기 때문에 생략 가능합니다.
struct {
char name[20];
int age;
double height;
double weight;
} data;
2. 구조체 사용하기
정의된 구조체는 구조체명을 이용하여 변수를 선언하듯이 선언해주면 되는데 C 언어에서 구조체를
이용하여 변수를 선언할 때에는 반드시 구조체명 앞에 "struct" 키워드를 붙여주어야합니다.
// People 구조체를 사용하여 data 변수를 선언한다.
struct People data;
C++ 언어로 구조체를 선언할 때에는 struct 키워드를 생략하여 선언할 수 있지만 C 언어의 경우에는
구조체를 선언할 때마다 struct 키워드를 명시해야 하기때문에 아래와 같이 typedef 명령어를 이용
하여 구조체를 또다른 데이터 타입으로 정의하여 사용하기도 합니다.
typedef struct People PEOPLE;
이렇게 선언하면 C 언어에서도 People 구조체를 사용하여 변수를 선언할때 struct 키워드를
적지 않게되어 좀더 편리하게 사용할수 있습니다.
PEOPLE data; // struct People data;
하지만, 구조체 정의 따로 typedef 정의 따로 사용하는 방식이 프로그램을 이해하기에 불편할수도
있기 때문에 이것을 아래와 같이 한번에 사용하여 구조체를 정의하기도 합니다.
// struct people { ... } 구조체를 PEOPLE 이라는 데이터형으로 정의한다.
typedef struct People{
char name[20];
int age;
double height;
double weight;
} PEOPLE;
// data 라는 변수명으로 people 구조체를 선언한다.
PEOPLE data;
최근에는 C++ 를 사용하는 사람들이 많아짐에따라 struct 가 생략가능해지면서 typedef 을 사용하는
형식도 점차 줄어들고 있습니다.
구조체로 선언한 데이터형도 기본데이터형(char, int, ...)과 동일한 데이터 형이기 때문에 변수 선언시
배열, 포인터 문법을 아래와 같이 그대로 사용할수 있습니다.
PEOPLE data; // 일반 변수
PEOPLE list[20]; // 배열
PEOPLE *p; // 포인터
이렇게 선언된 구조체 변수는 아래의 코드처럼 구조체의 요소에 접근할 때에는 " . " 를 이용하여
구조체의 "변수명.요소명" 과 같은 형식을 사용합니다.
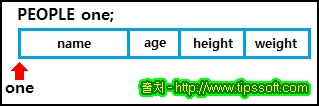
PEOPLE one;
strcpy(one.name, "운영진");
one.age = 23;
one.height = 179.9;
one.weight = 70;
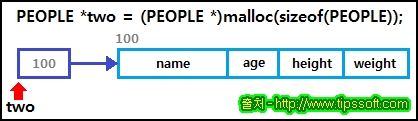
그리고 메모리를 동적으로 할당하여 선언하고, 사용하는 방법은 다음과 같습니다.
PEOPLE *two = (PEOPLE *)malloc(sizeof(PEOPLE));
strcpy((*two).name, "사용자");
(*two).age = 30;
(*two).height = 185;
(*two).weight = 75;
위 코드에서 *two.age 라고 하지 않고 (*two).age 라고 사용한 이유는 " * " 연산자보다 " . " 연산자의
연산자 우선순위가 높기때문에 정확한 표현을 하기 위해서입니다. 따라서 ( ) 를 생략하면 전혀
다른 의미로 해석되어 컴파일시에 오류가 발생합니다.
이렇게 연산자 우선순위 때문에 구조체를 포인터 형식으로 사용하면 ( ) 을 적어야 하는 불편함이
생기는데 이런 불편함을 줄여주기 위해서 C/C++ 에서는 " -> " 라는 약식 표현법이 제공됩니다.
이 약식 표현법으로 위 코드를 다시 적으면 아래와 같습니다.
PEOPLE *two = (PEOPLE *)malloc(sizeof(PEOPLE));
strcpy(two->name, "사용자");
two->age = 30;
two->height = 185;
two->weight = 75;
3. 구조체의 크기와 메모리 배열 ( struct member alignment )
구조체의 크기는 일반적으로 구조체를 구성하는 데이터형의 크기를 합산한 값입니다. 따라서
위에서 정의한 People 데이터형은 40 바이트 입니다. 하지만, VC++ 에서는 데이터 처리의
수행능력을 높이기 위해서 "struct member alignment" 을 사용하기 때문에 위 구조체의 크기가
40 바이트 일수도 아닐수도 있습니다.
Windows 32비트 운영체제는 레지스터의 크기, 데이터 버스의 크기, 데이터 처리 단위, 포인터의 크기
등이 모두 4 바이트로 되어 있어서 해당 크기로 연산하고, 처리하는 것이 속도가 더 빠릅니다. 그래서
컴파일 옵션에 따라서 구조체를 해석할때 그 배열을 짝수 또는 4의 배수로 재구성하는 작업을
수행하기 때문에 실제로 구조체가 구성되는 것이 조금 다를 수 있습니다.
( People 구조체는 다행이도 짝수 배열이 유지되어 struct member alignment 사용해도 크기가
동일하기 때문에 다른 구조체를 정의하여 설명하도록 하겠습니다. )
typedef struct Test {
char a; // 1 바이트의 데이터 크기를 가짐
int b; // 4 바이트의 데이터 크기를 가짐
short int c; // 2 바이트의 데이터 크기를 가짐
int d; // 4 바이트의 데이터 크기를 가짐
char e; // 1 바이트의 데이터 크기를 가짐
} TEST;
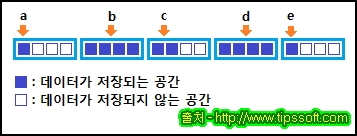
위와 같이 정의된 TEST 구조체를 선언하면 12 바이트의 메모리가 할당된다고 생각할 수도 있지만
구조체를 구성하고 저장하는 단위가 4 바이트이기 때문에 b 나 d 같은 4 바이트 이상의 크기를 가지는
변수가 4의 배수 주소 값에 위치하도록 아래와 같은 형태로 메모리가 사용되어 20 바이트의 메모리가
할당됩니다.
그렇기때문에 쓸데없는 메모리의 낭비를 막기 위해서는 아래와 같이 데이터를 구성하는 순서를
변경하여 구조체를 정의하는 것이 좋습니다.
typedef struct Test {
int b; // 4 바이트의 데이터 크기를 가짐
int d; // 4 바이트의 데이터 크기를 가짐
short int c; // 2 바이트의 데이터 크기를 가짐
char a; // 1 바이트의 데이터 크기를 가짐
char e; // 1 바이트의 데이터 크기를 가짐
} TEST;
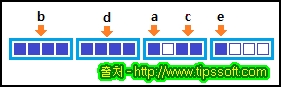
위와 같이 구조체를 정의하면 4의 배수 주소에 위치해야하는 b, d 가 선두에 먼저 배치되고 c, a, e 는
4바이트 내에 모두 저장되어 아래의 그림처럼 메모리 낭비가 생기지는 것을 볼 수 있습니다. 최악의
경우 20 바이트의 크기를 가졌던 구조체가 데이터의 배치만 변경하여 12 바이트의 크기로 줄어들게
되었습니다.
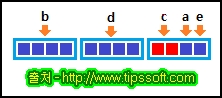
b, d 와 같은 4 의 배수 크기를 가진 데이터뿐만 아니라 c 변수같은 2 바이트의 크기를 가진 데이터는
짝수 주소에 저장되려는 특징이 있기때문에 c, a, e 순서로 정의하지 않고, 아래와 같이 a, c, e 순서로
정의하면 메모리가 아래의 그림처럼 구성되어서 16 바이트의 크기를 가지게 됩니다.
typedef struct Test {
int b; // 4 바이트의 데이터 크기를 가짐
int d; // 4 바이트의 데이터 크기를 가짐
char a; // 1 바이트의 데이터 크기를 가짐
short int c; // 2 바이트의 데이터 크기를 가짐
char e; // 1 바이트의 데이터 크기를 가짐
} TEST;
이처럼 구조체를 정의할 때 어떻게 배치하는가에 따라 구조체의 크기가 변경될 수 있기때문에
메모리를 낭비하지 않도록 주의해야하며, 프로그래밍을 하다가 구조체의 크기를 명시해야하는
경우에는 수치 값이 아닌 sizeof 매크로를 사용하여 구조체의 크기를 반환받아 사용해야합니다.
TEST *data = (TEST *)malloc(12); // 위험한 표현
TEST *data2 = (TEST *)malloc(sizeof(TEST)); // 안전한 표현