'프로그램 > MsSql' 카테고리의 다른 글
| expression을(를) 데이터 형식 int(으)로 변환하는 중 산술 오버플로 오류가 발생했습니다.[mssql] (0) | 2023.10.11 |
|---|---|
| MS-SQL 테이블 복사 (0) | 2019.09.27 |
| SCM 서비스 - 사용된 계정의 암호 변경 (0) | 2019.06.01 |
| sql서버 외부포트열기 (0) | 2017.10.25 |
| mssql코멘트 (0) | 2016.01.18 |
| expression을(를) 데이터 형식 int(으)로 변환하는 중 산술 오버플로 오류가 발생했습니다.[mssql] (0) | 2023.10.11 |
|---|---|
| MS-SQL 테이블 복사 (0) | 2019.09.27 |
| SCM 서비스 - 사용된 계정의 암호 변경 (0) | 2019.06.01 |
| sql서버 외부포트열기 (0) | 2017.10.25 |
| mssql코멘트 (0) | 2016.01.18 |
| expression을(를) 데이터 형식 int(으)로 변환하는 중 산술 오버플로 오류가 발생했습니다.[mssql] (0) | 2023.10.11 |
|---|---|
| MS-SQL 테이블 복사 (0) | 2019.09.27 |
| SCM 서비스 - 사용된 계정의 암호 변경 (0) | 2019.06.01 |
| sql서버 외부포트열기 (0) | 2017.10.25 |
| 사용자 비밀번호 (0) | 2016.02.11 |
TEdit를 비롯하여 EDIT 컨트롤에 숫자만 입력받도록 하는 방법은?
여러가지가 있겠지만
간단히 GWL_STYLE을 변경해주므로 가능합니다.
가끔 필요한데 생각이 나지 않아서 찾아야 하는데.. 찾는 수고를 덜기 위해서 여기에 ....
@C++Builder에서
void __fastcall TDLG_MANAGE::FormCreate(TObject *Sender) { SetWindowLong(Edit1->Handle,GWL_STYLE,GetWindowLong(Edit1->Handle,GWL_STYLE)|ES_NUMBER); } |
@ Delphi 에서
procedure TForm1.FormCreate(Sender: TObject); begin SetWindowLong(Edit1.Handle,GWL_STYLE,GetWindowLong(Edit1.Handle,GWL_STYLE) or ES_NUMBER); end; |
@기타 Edit Style
|
ES_AUTOHSCROLL |
에디트 컨트롤 내에 텍스트를 입력할 때 에디트 영역의 크기를 넘기면 자동으로 수평 스크롤된다. |
|
ES_AUTOVSCROLL |
여러 줄의 에디트 컨트롤 내에 텍스트를 입력할 때 자동으로 수직스크롤된다. |
|
ES_CENTER |
여러 줄의 에디트 컨트롤에서 텍스트를 가운데로 정령한다. |
|
ES_LEFT |
텍스트를 좌측으로 정렬한다. |
|
ES_LOWERCASE |
에디트 컨트롤에 소문자의 입력만을 허용한다. 대문자가 입력되면 자동으로 소문자로 바뀐다. |
|
ES_MULTILINE |
여러 줄의 에디트 컨트롤을 만든다. 엔터키를 개행 문자(Carriage Return)로 인식시키려면 ES_WANTRETURN 스타일을 이용해야 한다. |
|
ES_NOHIDESEL |
에디트 컨트롤에 입력 초점을 가지고 있지 않더라도 선택 영역 표시가 없어지지 않도록 한다. |
|
ES_NUMBER |
에디트 컨트롤에 숫자만이 입력될 수 있도록 한다. |
|
ES_OEMCONVERT |
입력된 텍스트는 Windows 문자셋에서 OEM 문자 세트로 변환되며 다시 Windows 세트로 되돌려진다. 이는 CharToOem 함수를 사용했을 때 변환이 정확히 일어나게 해준다. (OEM - See original equipment manufacturer.) |
|
ES_PASSWORD |
입력되는 각 문자를 암호 문자로 표시한다. 디폴트 암호 문자는 애스터리스크(*)이다. 암호문자를 변경 하려면 ES_SETPASSWORDCHAR 메시지를 이용한다. |
|
ES_READONLY |
읽기 전용 컨트롤을 생성하여 사용자가 컨트롤 내에 텍스트를 입력하거나 편집할 수 없도록 한다. |
|
ES_RIGHT |
여러 줄의 에디트 컨트롤에서 텍스트를 오른쪽으로 정렬한다. |
|
ES_UPPERCASE |
에디트 컨트롤에 대문자의 입력만을 허용한다. 소문자가 입력되면 자동으로 대문자로 바뀐다. |
|
ES_WANTRETURN |
엔터키를 여러 줄의 에디트 컨트롤에서 개행 문자로 인식하도록 한다. 디폴트는 엔터키를 주르면 대화 상자 내의 디폴트 버튼을 선택하게 되며 이 때에는 ctrl-enter 키가 개행 문자 역할을 한다. |
출처: http://www.nuno21.net/bbs/board.php?bo_table=vbcpp&wr_id=81
| 델파이 단축키 모음 (0) | 2017.10.17 |
|---|---|
| 델파이 공부에 도움 되는 자료들 모음 (0) | 2017.10.17 |
| 델파이 7.2 다운로드 (0) | 2017.10.10 |
| RAD Studio(델파이, C++빌더) 단축키 (0) | 2015.10.01 |
| 델파이 기본과정(동영상강좌) (0) | 2015.10.01 |
join문
6-1.full join
join 문중에서 가장 간단한 join문이라는 특징이 있으며 full join은 다음과 같이 설명할 수 있습니다.
>select * from tableA, tableB;
일반적인 join문은 양쪽 테이블의 레코드 갯수를 곱한 수만큼 검색을 하기 때문에 join을 사용할 때에는 주의해서 사용해야 합니다. 자칫 잘못걸린 join문은 검색속도를 저하시키고 전반적인 시스템의 성능저하를 유발시킬 수 있기 때문입니다.
다음의 예제는 full join의 형식과 일치하며 모두 같은 값을 출력합니다.
>select * from tableA, tableB;
>select * from tableA join tableB;
>select * from tableA cross join tableB;
6-2. straight_join
이 join문은 칼럼의 순서를 from절에 나오는 테이블의 순서대로 출력하는 join 입니다. 경우에 따라 MySQL은 속도를 빠르게 하기 위해 나름대로 내부적으로 from절에 나온 테이블의 순서를 바꾸는 경우가 있습니다. 이때 칼럼의 순서를 from 절에 나오는 순서대로 바꾸기 위해 straight_join을 사용하면 되니다.
6-3 theta join
full join문에 where 를 걸게 되면 theta join입니다.
>select * from tableA, tableB where
->tableA.b=tableB.b;
6-4. inner join
>select * from tableA INNER JOIN tableB USING(b);
또는
>select * from tableA INNER JOIN tableB ON
->tableA.b=tableB.b;
where절 대신에 ON을 사용하여 비교하고자 하는 컬럼을
직접 지정해 주는 방식. USING는 지정된 공통컬럼명을
ON으로 지정한것과 동일한 효과를 가짐.
6-5. NATURAL JOIN
두개의 테이블에 같은 이름을 가진 컬럼들이 있고
그 컬럼들을 기준으로 join을 하려 한다면 natural join을
사용합니다.
>select * from tableA natural join tableB;
추가 예제)
join문을 사용할 때 select 되는 컬럼의 지정방법
select tableA.x, tableB.x from tableA, tableB;
같은 결과 alias를 사용한 방법
select a.x, b.x from tableA as a, tableB as b;
6-6. left outer join
tableA와 tableB 를 join하여 검색할때 where 절의
tableA.b=tableB.b라고 검색하면 두 테이블의 b컬럼에
일치하는 data만을 불러 오지만 만약 tableB.b의 값이
tableA.b에 존재하지 않는 값을 가지고 있는 레코드까지
가져와야 할 경우 사용.
>select * from tableA left outer join tableB using(b);
ex)
>select * from grade left outer join study_report
->using(student_name);
6-7. right outer join
left outer join과는 반대의 개념으로
tableA와 tableB을 join하여 검색할 경우 tableB
기준으로 tableA에 값이 존재 하지 않는 것을
가져와야 할 경우 사용
※ 참고
outer 는 명시적 옵션이므로 생략가능
| MYSQL 사용자 생성 (0) | 2016.11.29 |
|---|---|
| PASSWORD()와 OLD_PASSWORD() 함수 그리고 old_passwords 설정 (0) | 2016.11.28 |
| MySQL 계열의 FLUSH PRIVILEGES 명령어 (0) | 2016.11.28 |
| MySQL 내장 함수 (MySQL전용 함수) (0) | 2016.11.28 |
| MySQL 기본 명령어 정리 (0) | 2016.11.28 |
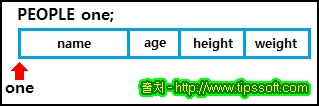
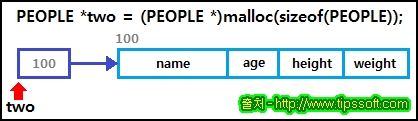
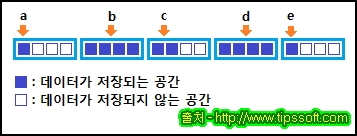
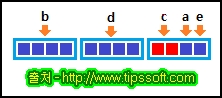
| 값에 의한 호출(call by value)과 참조에 의한 호출(call by reference)에 대한 이해 C언어 (0) | 2016.12.05 |
|---|---|
| [C] 스택(Stack), 힙(Heap), 데이터(Data)영역 (0) | 2016.11.29 |
| C언어] switch 문 (스위치) 사용법 예제; switch-case-default Statement x함수 (0) | 2016.11.29 |
| C언어 포인터 기본에 대해서 배워보도록 하자. (0) | 2016.11.29 |
| "Editplus" 와 "Visual Studio 2010" 컴파일러 연동하기 (0) | 2015.10.01 |
RAD Studio(Delphi, C++빌더) 단축키 입니다.
(엠바카데로 문서 자동 번역 후 일부 보정했습니다.)
컴파일 시 여러건의 오류를 이동하는 단축키를 묻는 분이 있어 찾아보니 Alt + F7, Alt + F8이 있었네요.(저도 모르고 여지껏 마우스로 클릭했네요.^^)
다양한 단축키 알아두시면 개발도 빠르게 하고, 디버깅도 빠르게 할 수 있겠네요.
| 바로 가기 | 작업 |
|---|---|
Alt + [ | 해당 구분 기호를 찾습니다 (앞으로). |
Alt + ] | 해당 구분 기호를 찾습니다 (역방향). |
Alt + ← | Alt + ↑ 또는 Ctrl + 클릭 (선언 부로 이동) 작업 이전 위치로 돌아갑니다. |
Alt + F7 | Messages View에 표시되기 전에 오류 또는 메시지의 위치로 이동합니다. |
Alt + F8 | Messages View에 표시된 다음 오류 또는 메시지의 위치로 이동합니다. |
Alt + PgDn | 다음 탭으로 이동합니다. |
Alt + PgUp | 이전 탭으로 이동합니다. |
Alt + → | Alt + ← 작업 이전 위치로 이동합니다. |
Alt + Shift + ↓ | 커서를 한 줄 아래로 이동하여 원래의 커서 위치의 오른쪽에서 단일 열에을 선택합니다. |
Alt + Shift + End | 커서 위치부터 현재 줄의 끝까지 선택합니다. |
Alt + Shift + Home | 커서 위치부터 현재 줄의 처음까지 선택합니다. |
Alt + Shift + ← | 왼쪽의 열을 선택합니다. |
Alt + Shift + PgDn | 커서를 한 화면 아래로 이동하고 원래의 커서 위치를 유지합니다. |
Alt + Shift + PgUp | 커서를 한 화면 위로 이동하고 원래의 커서 위치를 유지합니다. |
Alt + Shift + → | 오른쪽의 열을 선택합니다. |
Alt + Shift + ↑ | 커서를 한 줄 위로 이동하여 원래의 커서 위치의 오른쪽에서 단일 열에을 선택합니다. |
Alt + ↑ | 선언 부로 이동합니다. |
Click + Alt + Mousemove | 열 단위 블록을 선택합니다. |
Ctrl + / | 선택한 코드 블록의 각 행에 // 를 추가하여 코드를 주석으로 처리하거나, 제거합니다. |
Ctrl + Alt + F12 | 열려있는 파일의 드롭 다운 목록을 표시합니다. |
Ctrl + Alt + Shift + End | 커서 위치에서 화면의 끝까지 열을 선택합니다. |
Ctrl + Alt + Shift + Home | 커서 위치에서 화면의 시작까지 열을 선택합니다. |
Ctrl + Alt + Shift + ← | 왼쪽의 열을 선택합니다. |
Ctrl + Alt + Shift + PgDn | 커서 위치에서 현재 파일의 끝까지 열을 선택합니다. |
Ctrl + Alt + Shift + PgUp | 커서 위치에서 현재 파일의 시작 부분까지 열을 선택합니다. |
Ctrl + Alt + Shift + → | 오른쪽의 열을 선택합니다. |
Ctrl + BackSpace | 커서의 왼쪽으로 한 단어를 삭제합니다 (앞의 공백까지의 문자가 삭제됩니다.) |
Ctrl + Click | 선언 부로 이동합니다. |
Ctrl + Delete | 현재 선택된 블록을 삭제합니다. |
Ctrl + ↓ | 아래에 한 줄 스크롤합니다. |
Ctrl + End | 파일의 끝으로 이동합니다. |
Ctrl + Enter | 커서 위치의 파일을 엽니 다. |
Ctrl + Home | 파일의 시작 부분으로 이동합니다. |
Ctrl + I | 커서 위치에 탭 문자를 삽입합니다. |
Ctrl + J | 템플릿 팝업 메뉴를 엽니 다. |
Ctrl + K + n | 커서 위치에 책갈피 설정 ( n 은 0 ~ 9의 숫자). |
Ctrl + K + E | 현재 단어를 소문자로 변환합니다. |
Ctrl + K + F | 현재 단어를 대문자로 변환합니다. |
Ctrl + K + T | 커서 위치의 한 단어를 선택합니다. |
Ctrl + ← | 한 단어 왼쪽으로 이동합니다. |
Ctrl + n | 책갈피로 이동합니다 ( n 은 0-9의 책갈피 번호). |
Ctrl + N | 커서 위치에 줄 바꿈을 삽입합니다. |
Ctrl + O + C | 열 단위 블록 모드를 선택합니다. |
Ctrl + O + K | 열 단위 블록 모드를 해제합니다. |
Ctrl + O + L | 행 방향 블록 모드를 선택합니다. |
Ctrl + O + O | 컴파일러 옵션을 삽입합니다. |
Ctrl + P | 다음 문자를 ASCII 시퀀스로 해석합니다. |
Ctrl + PgDn | 화면의 맨 아래로 이동합니다. |
Ctrl + PgUp | 화면 상단으로 이동합니다. |
Ctrl + Q + # | 커서 위치에 책갈피를 설정합니다. |
Ctrl + → | 한 단어 오른쪽으로 이동합니다. |
Ctrl + Shift + C | 커서 위치의 클래스 선언에 대응하는 클래스 보완을 시작합니다. |
Ctrl + Shift + # | 커서 위치에 책갈피를 설정합니다. |
Ctrl + Shift + B | 버퍼 목록을 표시합니다. |
Ctrl + Shift + ↓ | 선언에서 구현 또는 구현에서 선언으로 이동합니다. |
Ctrl + Shift + Enter | 사용 항목을 검색합니다. |
Ctrl + Shift + J | 동기화 편집 모드를 선택합니다. |
Ctrl + Shift K-A | 모든 코드 블록을 확장합니다. |
Ctrl + Shift K + C | 모든 클래스를 축소합니다. |
Ctrl + Shift K + E | 코드 블록을 축소합니다. |
Ctrl + Shift K-G | 초기화 / 종료 또는 인터페이스 / 구현 |
Ctrl + Shift K + M | 모든 메서드를 축소합니다. |
Ctrl + Shift K + N | 네임 스페이스 / 단위를 축소합니다. |
Ctrl + Shift K + O | 코드 축소를 활성화 또는 비활성화 전환합니다. |
Ctrl + Shift K + P | 중첩 된 절차를 축소합니다. |
Ctrl + Shift K + R | 모든 영역을 축소합니다. |
Ctrl + Shift K-T | 현재 블록의 축소 및 확장을 전환합니다. |
Ctrl + Shift K-U | 코드 블록을 확장합니다. |
Ctrl + Shift + End | 커서 위치에서 현재 파일의 끝까지 선택합니다. |
Ctrl + Shift + G | 새로운 글로벌 고유 식별자 (GUID)를 삽입합니다. |
Ctrl + Shift + Home | 커서 위치에서 현재 파일의 처음까지 선택합니다. |
Ctrl + Shift + I | 선택된 블록을 들여 씁니다. |
Ctrl + Shift + ← | 커서의 왼쪽으로 한 단어를 선택합니다. |
Ctrl + Shift + P | 기록 된 키 스트로크 매크로를 재생합니다. |
Ctrl + Shift + PgDn | 커서 위치에서 화면의 하단까지를 선택합니다. |
Ctrl + Shift + PgUp | 커서 위치에서 화면 상단에서을 선택합니다. |
Ctrl + Shift + R | 키 스트로크 매크로 기록 시작 / 정지를 전환합니다. |
Ctrl + Shift + → | 커서의 오른쪽으로 한 단어를 선택합니다. |
Ctrl + Shift + Space | 코드 파라미터 팝업 창을 엽니 다. |
Ctrl + Shift + T | [To-Do 항목 추가 대화 상자를 엽니 다. |
Ctrl + Shift + Tab | 이전 코드 페이지 (또는 파일)로 이동합니다. |
Ctrl + Shift + Tab | 이전 페이지로 이동합니다. |
Ctrl + Shift + U | 선택된 블록 들여 쓰기를 해제합니다. |
Ctrl + Shift + ↑ | 선언에서 구현 또는 구현에서 선언으로 이동합니다. |
Ctrl + Shift + Y | 커서 위치부터 줄 끝까지 삭제합니다. |
Ctrl + Space | 코드 완성 팝업 창을 엽니 다. |
Ctrl + T | 오른쪽으로 한 단어를 삭제합니다 (다음 스페이스까지의 문자가 삭제됩니다.) |
Ctrl + Tab | 다음 코드 페이지 (또는 파일)로 이동합니다. |
Ctrl + ↑ | 한 행 위로 스크롤합니다. |
Ctrl + Y | 현재 행을 삭제합니다. |
F1 | 선택된 정규화 된 네임 스페이스의 도움말을 표시합니다. |
Shift + Alt + arrow | 열 단위 블록을 선택합니다. |
Shift + BackSpace | 커서의 왼쪽 문자를 삭제합니다. |
Shift + ↓ | 커서를 한 화면 아래로 이동하여 원래의 커서 위치의 오른쪽에서 현재 위치까지 선택합니다. |
Shift + End | 커서 위치부터 현재 줄의 끝까지 선택합니다. |
Shift + Enter | 커서 위치에 새 줄을 삽입합니다. |
Shift + Home | 커서 위치부터 현재 줄의 처음까지 선택합니다. |
Shift + ← | 커서의 왼쪽 문자를 선택합니다. |
Shift + PgDn | 커서를 한 화면 아래로 이동하여 원래의 커서 위치의 오른쪽에서 현재 위치까지 선택합니다. |
Shift + PgUp | 커서를 한 화면 위로 이동하여 원래의 커서 위치의 왼쪽에서 현재 위치까지 선택합니다. |
Shift + → | 커서의 오른쪽 문자를 선택합니다. |
Shift + Space | 공백을 삽입합니다. |
Shift + Tab | 커서를 왼쪽으로 한 탭 위치로 이동합니다. |
Shift + ↑ | 커서를 한 줄 위로 이동하여 원래의 커서 위치의 왼쪽에서 현재 위치까지 선택합니다. |
| 델파이 단축키 모음 (0) | 2017.10.17 |
|---|---|
| 델파이 공부에 도움 되는 자료들 모음 (0) | 2017.10.17 |
| 델파이 7.2 다운로드 (0) | 2017.10.10 |
| EDIT 컴포넌트 숫자만 입력, 오른쪽 정렬 등등 (0) | 2015.10.14 |
| 델파이 기본과정(동영상강좌) (0) | 2015.10.01 |
"Editplus" 와 "Visual Studio 2010" 컴파일러 연동하기
C/C++ 코딩을 할 때 알고리즘을 풀이 하거나 기본적인 테스트를 위해서
Visual Studio를 실행하면 너무 무겁기에 Editplus 를 사용하는 편이다.
하지만 Editplus는 컴파일러가 내장되어 있지 않기 때문에 Visual Studio에 있는 컴파일러를 사용하기로 한다.
먼저 환경변수 등록을 해야 한다.
[컴퓨터] -> [속성] -> [고급 시스템 설정] -> [환경변수]
[시스템 변수]
1. Path 항목에 2가지를 추가한다.
C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin
C:\Program Files (x86)\Microsoft Visual Studio 10.0\Common7\IDE
2. 새로 만들기를 눌러 "LIB" 항목을 새로 만들고 다음 경로를 추가한다.
C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\lib
3. 새로 만들기를 눌러 "INCLUDE" 항목을 새로 만들고 다음 경로를 추가한다.
C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\include
★ 경로를 추가할 때 다른 값들과 구별되기 위해서 세미콜론 ";"을 반드시 넣도록 한다. ★
------------------------------------------------------------------------------------------
그 다음은 EditPlus 에서의 설정 내용
[도구] -> [사용자 도구 구성] -> [Group1] 에서 -> [추가>>]
메뉴제목 : C/C++ Compile (적당히 적는다.)
명령 : C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\cl.exe
인수 : $(FilePath)
디렉토리 : $(FileDir)
(출력 내용 캡처 항목을 체크한다.)
메뉴제목 : Run (적당히 적는다.)
명령 : $(FileNameNoExt)
인수 :
디렉토리 : $(FileDir)
★ EditPlus 설정을 마치면 적용을 누르고 프로그램을 종료하고 다시 켜야한다. ★
컨트롤 + 1 => 컴파일
컨트롤 + 2 => 실행
다음과 같이 내용이 출력되면 제대로 설정되었다.
★ 하지만 kernel32.lib 파일이 없다고 나올 경우 ★
C:\Program Files (x86)\Microsoft SDKs\Windows\v7.0A\Lib 여기서 Kernel32.lib 파일을 찾아서
C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\lib 이쪽으로 복사 붙여넣기 해준다.
| 값에 의한 호출(call by value)과 참조에 의한 호출(call by reference)에 대한 이해 C언어 (0) | 2016.12.05 |
|---|---|
| [C] 스택(Stack), 힙(Heap), 데이터(Data)영역 (0) | 2016.11.29 |
| C언어] switch 문 (스위치) 사용법 예제; switch-case-default Statement x함수 (0) | 2016.11.29 |
| C언어 포인터 기본에 대해서 배워보도록 하자. (0) | 2016.11.29 |
| C언어 구조체 (0) | 2015.10.05 |
| 델파이 단축키 모음 (0) | 2017.10.17 |
|---|---|
| 델파이 공부에 도움 되는 자료들 모음 (0) | 2017.10.17 |
| 델파이 7.2 다운로드 (0) | 2017.10.10 |
| EDIT 컴포넌트 숫자만 입력, 오른쪽 정렬 등등 (0) | 2015.10.14 |
| RAD Studio(델파이, C++빌더) 단축키 (0) | 2015.10.01 |
























